Enterprise data lineage for modern data management

Data lineage has always been foundational for enterprise environments. It powers discovery, governance, optimization, and now, also AI readiness.
You need lineage when you’re cleaning up a cluttered warehouse and asking: Can I safely delete this table, or is something critical downstream? You need it when teams are stuck in Slack threads asking: Where does this metric actually come from? Why is it different across dashboards? You need it when preparing your stack for AI and asking: Which tables are trusted, which are out of sync, and which contain conflicting logic?
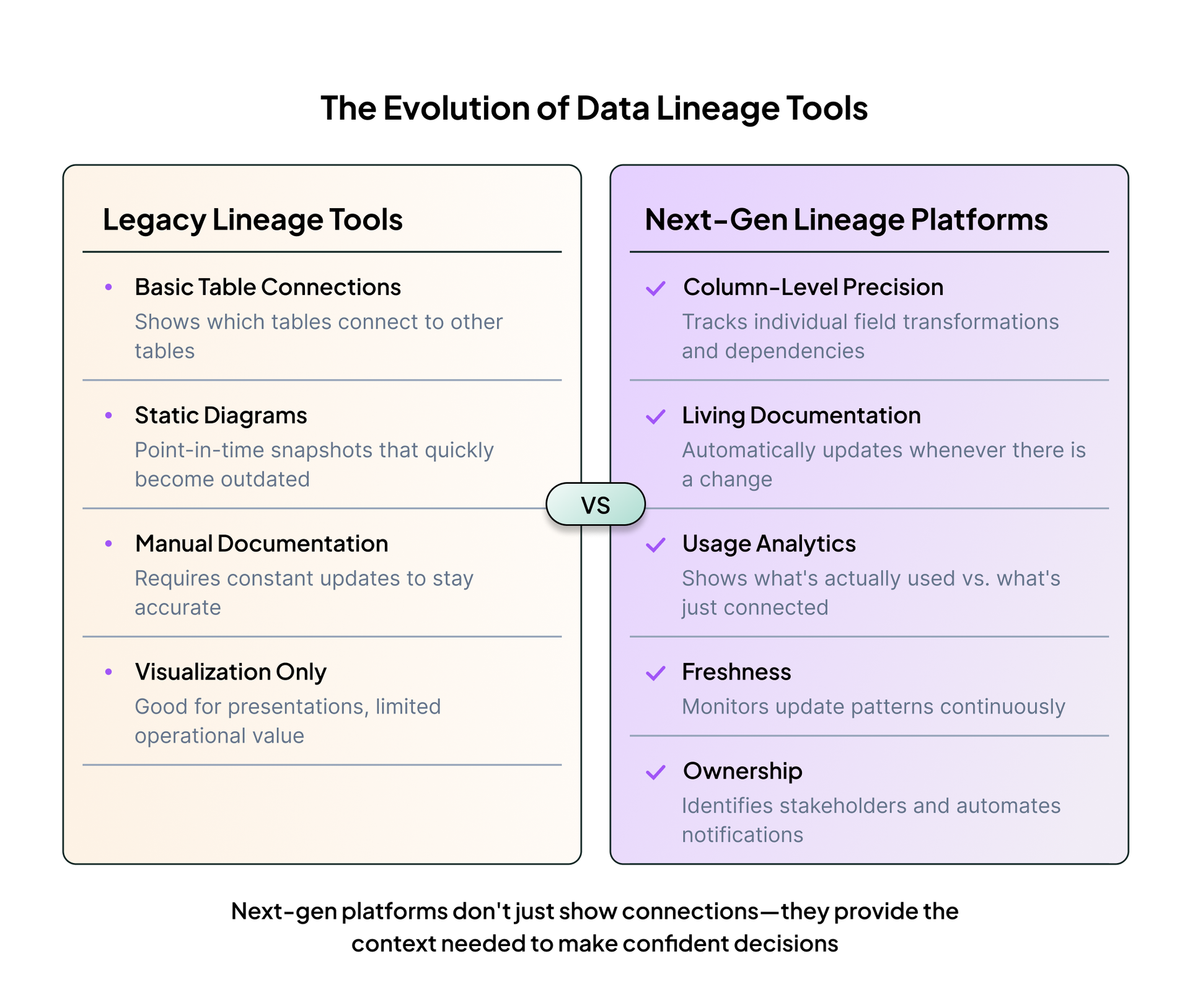
These challenges have evolved, but most lineage tools haven’t. They’re still showing you static diagrams: arrows pointing from table A to table B. That’s not enough. When you need to make real decisions, you need additional context: Is anyone actually using this pipeline? Who owns it? When did it last run successfully?
A new generation of lineage platforms understands this gap. They stitch together usage, ownership, transformation code, and semantic definitions into a living system that actually helps you answer questions and make decisions.
This guide explores what enterprise-grade, AI-ready data lineage looks like in 2025, and how to evaluate tools that move beyond visualization to real operational value.
What is enterprise data lineage in 2025?
For years, companies treated lineage as documentation, something you maintain for compliance and forget about until audit time. That approach doesn’t work anymore.
Modern lineage has evolved into operational infrastructure. Think of it as the nervous system of your data stack, constantly mapping how data flows through your warehouse, dashboards and metrics. Unlike the static diagrams of the past, today’s lineage updates in real-time, capturing every change as it happens.
But here’s where most tools still fall short: they show you connections without context.
Knowing that Table A feeds Dashboard B is only the start. Modern platforms integrate critical metadata directly into the lineage graph:
- Is anyone actually viewing that dashboard?
- Who owns this pipeline if it breaks?
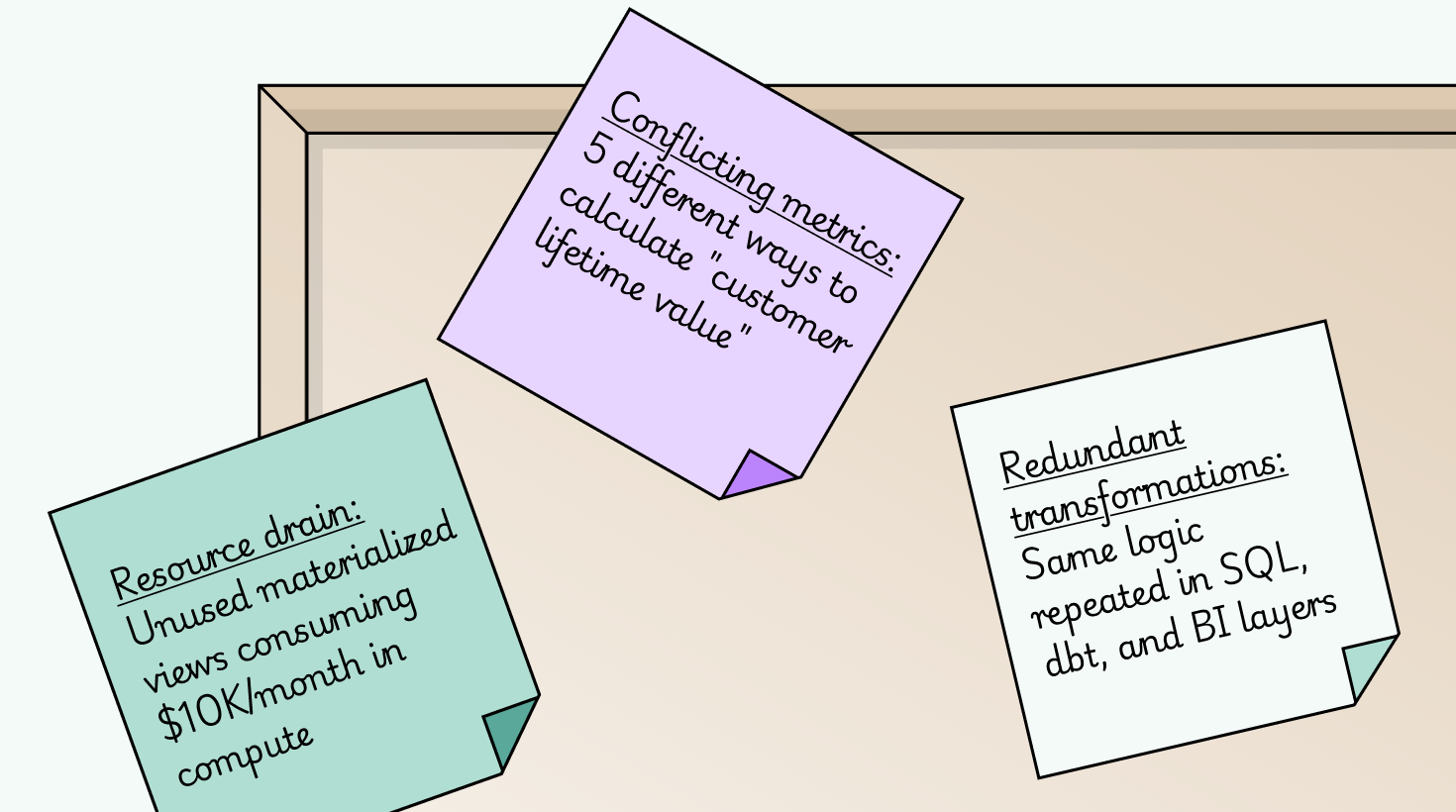
- Are these two “revenue” calculations actually calculating the same thing?
That’s why the leading platforms now integrate usage analytics, ownership mapping, and semantic understanding directly into the lineage graph. These aren’t separate tools, they’re intelligence layers that flow through your data’s structure.
- If you want to understand how often a table is used, you don’t just look at direct queries. You trace the lineage to dashboards downstream, and attribute back the sum of their usage.
- If you’re preparing a schema change, you don’t want a list of everything connected. You want to know what’s used, what’s stale, and who needs to take action.
This transforms lineage from a compliance checkbox into an operational powerhouse. It drives faster debugging, cleaner data stacks, and confident AI implementations.
Why data lineage is cornerstone to modern data management
Understanding why lineage has become critical and not just useful, requires examining how data management has changed:
1. Data ownership has fundamentally changed
Gone are the days when a single team controlled all the data. Today’s reality? Your platform engineers are building pipelines, analytics teams are creating metrics, and business users are spawning dashboards faster than you can document them.
Lineage is what keeps this distributed chaos manageable. It’s the connective tissue that helps everyone understand how their work affects others, even as teams reorganize and tools change quarterly.
2. Governance that actually prevents problems
Traditional governance feels like detective work: something broke, users are complaining, and now you’re doing forensics to figure out what went wrong.
Modern lineage enables proactive governance:
- Pre-deployment impact analysis: See exactly what breaks before pushing changes
- Automated compliance tracking: PII classifications propagate automatically through transformations
- Quality Gates: Block deployments that would break critical downstream assets
This shift from reactive to proactive governance reduces incidents by 70% or more in organizations that fully adopt it.
3. You can’t optimize what you can’t see
Every data stack has hidden waste: duplicate pipelines running the same transformations, forgotten tables consuming compute, test data that powers a dashboard nobody uses.
Lineage makes this waste visible. But when you layer in usage data, it becomes actionable. Now you know which of those 50 connected tables actually matter, which pipelines can be sunset, and which migrations will be painless versus painful.
4. One view that everyone actually understands
Ask five people where a metric comes from, get five different answers. Sound familiar? Without lineage, every team develops their own mental model of how data flows. A proper lineage platform becomes the single source of truth everyone can reference. No more archeological digs through transformation logic. No more “I think this table feeds that dashboard.” Just clear, current answers.
5. AI needs structure to be useful, not misleading
LLMs without context are just confident guessing machines. Ask an AI about your data relationships without access to reliable lineage, and it will hallucinate connections that sound plausible but don’t exist.
Lineage provides the structural context AI needs to reason accurately about your data. It establishes trust boundaries, traces actual relationships, and prevents the kind of errors that make stakeholders lose faith in AI initiatives. Without lineage, AI is just another tool that sounds impressive but breaks in production.
5 core capabilities of next-gen data lineage platforms
The difference between legacy and next-generation lineage is fundamental architecture. Here’s what sets modern platforms apart:
Cross-layer, cross-platform Intelligence
Your data doesn’t respect tool boundaries. It flows from Snowflake to dbt, transforms through Airflow, and surfaces in Tableau. Next-gen platforms don’t just map these connections, they understand how signals propagate through each layer.
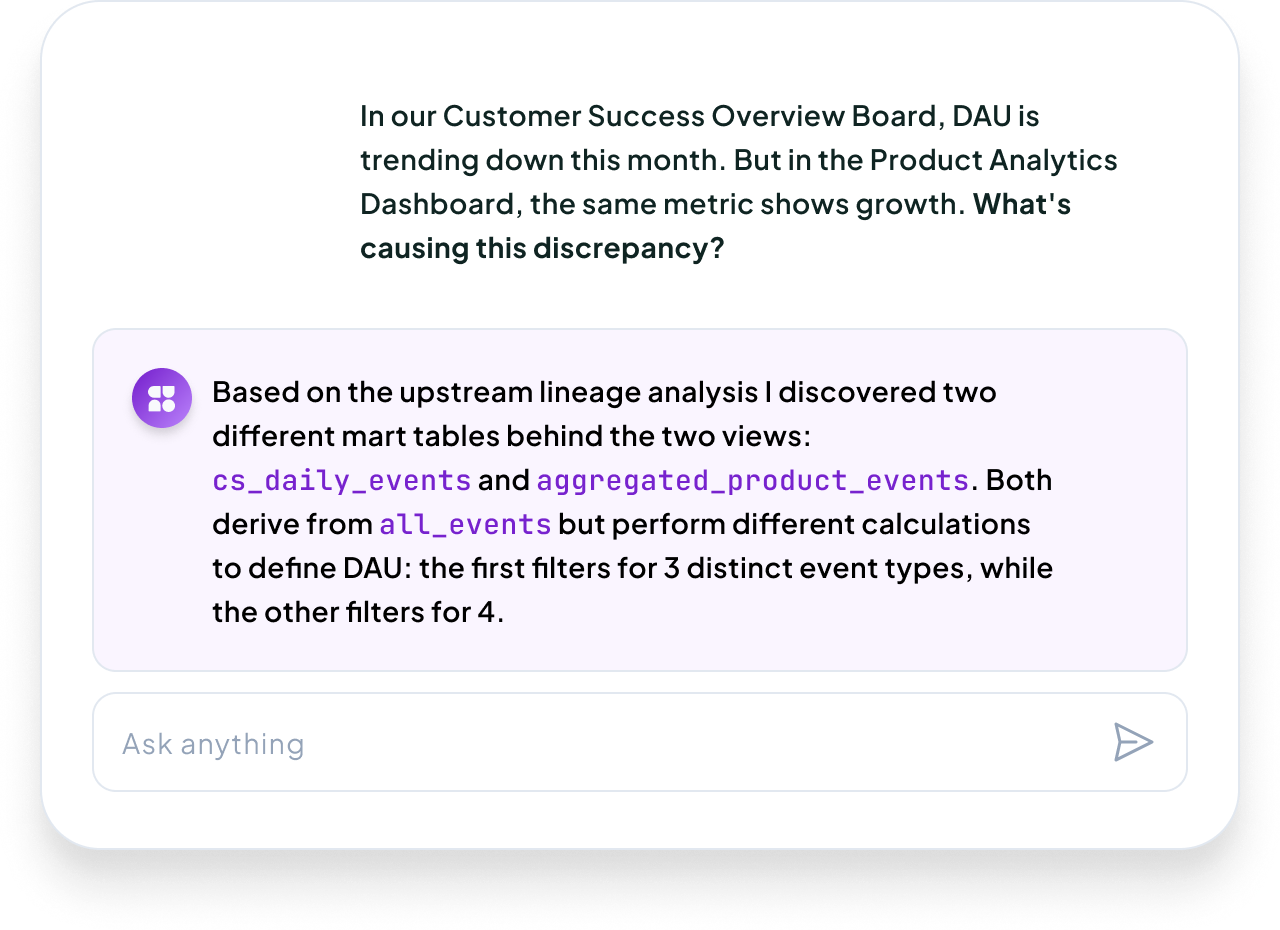
When someone views a dashboard, that usage signal doesn’t stop at the BI layer. It flows backward through the lineage graph, all the way to the source tables. Now you know that your raw_customer_events table isn’t just connected to 50 objects; it’s actually powering three critical dashboards that were viewed over 200 times in the last 30 days.
The same intelligence propagates forward. When you tag a column as containing PII data, that classification flows through every transformation and model, automatically flagging every derived field and dashboard that might expose sensitive information.

Column-level precision
Column-level lineage shows you that the customer_id in your fact table specifically feeds the user segmentation in your retention dashboard, and that the revenue field gets transformed three times before becoming your “ARR” metric.
When numbers don’t match, you can trace the exact transformation logic for specific fields, not just general table relationships.
Multiple ways to access intelligence
The best platforms recognize that different users need different interfaces:
- Visual graphs for exploring relationships and understanding impact at a glance
- Tabular views for systematic analysis and bulk operations
- Query interfaces for complex questions (“Show me all tables created by team X that feed dashboards owned by team Y and are highly used”)
- Natural language access for business users (“Why doesn’t the MRR for last month in the executive dashboard match the ARR for last month in the sales by geography dashboard?”)
Automations
Manual processes break at scale. Next-gen platforms automate the workflows that matter:
- Smart notifications: When you modify a table, owners of affected dashboards get notified automatically, —with context about what changed and potential impact
- Policy enforcement: Set rules for production readiness, naming convention etc, and flags assets that don’t comply
- Scheduled audits: Automatically identify unused assets or inconsistent definitions.
Impact analysis
“What happens if I change this?” shouldn’t require a prayer and a test in production. Modern impact analysis combines structural lineage with contextual intelligence:
- See not just what breaks, but what matters (based on usage)
- Understand not just technical dependencies, but business impact
- Get not just a list of affected objects, but a prioritized action plan
The platform should tell you: “This change affects 12 tables, 3 of which are actively used. Here are the 2 dashboard owners you need to coordinate with.
How embedding AI in lineage enhances data engineering productivity
AI is already embedded in many aspects of how we work: from assisting with SQL to generating documentation. But one of its biggest untapped potential is in lineage. When LLMs are layered onto a rich, connected lineage graph, engineers can interact with it, govern it, and automate it.
Here’s how embedding AI in lineage changes the game.
Query the graph
AI-native platforms let engineers ask:
“Which dashboards use fields from stg_orders?”
“What depends on the user_id column in product?”
“Is anything downstream of this model uncertified?”
The AI assistant parses the question, traverses the lineage graph, and returns an answer, filtered by usage, ownership, and semantic rules. No manual tracing needed.
Define governance rules and enforce them through lineage
Modern lineage platforms use AI to analyze unstructured metadata — like names, code, and descriptions — to detect patterns and apply governance rules automatically.
Teams can define custom properties such as:
- has_fanout_join
- meets_naming_convention
- eligible_for_production
These aren’t static tags. They’re calculated dynamically based on lineage and logic, and they propagate upstream or downstream depending on how the data flows.
Examples:
- A model with a fan-out join flags dependent assets as risky.
- A misnamed table prevents downstream certification.
- A model that meets all quality checks is marked as production-ready — and that status flows through the graph.
Define the rule once. The system enforces it everywhere.

What to look for in your data lineage tool?
Selecting the right data lineage platform can significantly impact your organization’s data governance, operational efficiency, and AI readiness. Here’s a concise guide to critical capabilities you should prioritize in your evaluation process:
Core lineage capabilities
Ensure the platform supports automated,column-level lineage mapping across your entire data stack, dynamically tracing data across multiple layers, —from warehouses and lakes through transformation tools to BI dashboards. Confirm it updates lineage automatically in response to metadata changes without manual intervention.
Architecture & performance
Evaluate the underlying architecture. Graph databases typically offer superior performance for complex lineage queries. Confirm the platform’s responsiveness by asking for query response benchmarks, especially for extensive transformation layers and complex queries (e.g., tracing sensitive data flows).
Integration flexibility
Your lineage solution must integrate seamlessly with your existing stack. Verify compatibility with:
- Data Warehouses
- Data Lakes
- Transformation Tools
- ETL Pipelines
- BI Tools
Lineage enrichment & metadata
Confirm that the tool enriches lineage with usage metrics, asset freshness, governance policies, and ownership details. Critical features include signal propagation: for instance, automatically propagating PII or certification flags throughout the lineage.
Customizability & governance
Prioritize solutions that allow the creation of dynamic, calculated metadata fields influenced directly by lineage (e.g., tracking upstream queries only from the Gold Layer). Ensure the platform supports bidirectional metadata propagation (e.g., usage signals flowing upstream, sensitivity flags flowing downstream).
Lineage investigation & user experience
Look for intuitive interfaces and versatile exploration options:
- Interactive lineage graphs with collapsible and expandable views
- Filterable views based on custom criteria
- Support for structured query languages
- Natural language querying capability
Consider platforms that provide multiple interaction modes suitable for both technical and business users.
AI capabilities
AI-driven features enhance usability significantly. Assess:
- Natural language query interpretation specific to your organizational data context
- Automated detection for lineage-related issues
- AI-generated explanations of complex lineage paths for quick understanding
Impact analysis & operational features
Robust lineage platforms should offer detailed, field-level impact analysis reports. They should identify impacted assets and stakeholders clearly and prioritize recommendations. Integrating with CI/CD pipelines to proactively assess and block risky schema changes (e.g., PR merges) is essential for proactive governance.
Total cost of ownership
Understanding the true cost of your lineage platform involves more than upfront licensing:
- Clarify additional licensing costs for essential features like API access and column-level lineage
- Determine required resources (FTEs) for initial setup and ongoing maintenance
Scalability & enterprise readiness
Confirm the solution’s scalability, ensuring it can handle large enterprise workloads efficiently. Essential enterprise-grade features include multi-tenancy, role-based access control, and adherence to stringent security standards.
Use these guidelines to comprehensively evaluate potential lineage solutions, ensuring you select a tool that aligns strategically with your organization’s long-term data management and governance goals.

Enterprise lineage tools: A comparison for data leaders
The lineage tool market has matured significantly, with established players and newer entrants taking different approaches to the same fundamental challenge. Here’s how the leading platforms stack up for enterprise data governance and management.
1. Euno
Euno redefines enterprise data lineage by addressing the evolving needs of enterprise data leaders:
- GraphDB-Native Architecture: Euno’s foundation on a graph database enables precise and scalable lineage modeling, capturing complex relationships across data assets.
- Intuitive User Interface: Designed with both data practitioners and business users in mind, Euno offers an easy-to-navigate UI that facilitates collaboration and understanding.
- Impact Analysis Reports: Euno provides comprehensive reports to assess the downstream effects of changes, aiding in proactive decision-making and risk mitigation.
- AI Assistant: Users can interact with Euno using natural language queries, simplifying the process of exploring lineage and metadata catalogs.
- Automated Enrichment: Euno automates the enrichment of data with custom logic minimizing manual overhead and ensuring up-to-date metadata.
By integrating these features, Euno addresses common challenges faced with legacy solutions, offering a more dynamic and user-centric approach to metadata management and data governance.
2. Collibra
Collibra is recognized for its comprehensive data governance features, including metadata management and policy enforcement. However, some users find its setup process lengthy and its flexibility limited — making it best suited for large organizations with established governance programs.
3. Informatica Enterprise Data Catalog (EDC)
Informatica Enterprise Data Catalog (EDC) excels at scanning legacy systems and complex stored procedures that newer tools miss. The object-based licensing model creates budget surprises, and users report it’s “too costly and a bit complex because of a ton of features it provides”
4. Atlan
Atlan provides an AI-powered, metadata-driven platform that integrates across modern tools. It emphasizes active metadata and collaboration, but its rapid growth comes with tradeoffs — including segmented features and onboarding complexity. It’s a good fit for data teams embracing the modern stack and willing to invest in configuration.
5. Alation
Alation blends AI-driven discovery with lineage visualization, offering rich data flow tracking. However, its enterprise-first orientation prioritizes power over usability, and it struggles to integrate seamlessly with newer data architectures. It suits organizations with mature stewardship practices and budget flexibility.
6. Coalesce (formerly CastorDoc)
Coalesce (formerly CastorDoc) f(formerly CastorDoc) focuses on intuitive documentation and usability, achieving strong user satisfaction scores. However, its governance depth and architectural flexibility lag behind more mature players. It’s ideal for Snowflake-centric teams prioritizing ease of use over control.
7. Microsoft Purview
Microsoft Purview delivers comprehensive data governance solutions with seamless integration into the Azure ecosystem. However, it has limitations with data lineage, requiring manual work and facing challenges in connecting to non-Microsoft sources.
8. DataHub
DataHub is an open-source platform with strong support for column-level lineage, integrating with various data sources like Databricks, BigQuery, and Snowflake. It supports recording governance information through standardized business glossaries, allowing the definition of relationships between terms across glossaries.
Conclusion
Data lineage has evolved far beyond compliance, today, it’s essential operational infrastructure for modern enterprises.
Euno understands that data teams need more than pretty lineage diagrams. You need to know which tables actually matter, which metrics conflict, and what breaks when you push changes. That’s why we built lineage that’s operational, not just observational: intelligence that prevents problems instead of just documenting them.
See the difference in action: Book a demo, or download our RFP template to guide your evaluation process.
Frequently Asked Questions (FAQs)
- What is data lineage, and why is it important?
Data lineage tracks the path data takes through various systems: from its origin to its consumption. It’s essential for understanding dependencies, enabling proactive governance, optimizing your data stack, and supporting trustworthy AI applications. - How does next-gen lineage differ from traditional lineage tools?
Next-generation lineage solutions integrate real-time updates, usage analytics, ownership, governance signals, and AI-driven queries directly into lineage graphs. Unlike static diagrams, these modern tools provide actionable insights for decision-making and automation. - What key features should I look for in a data lineage platform?
Look for automated, column-level lineage mapping, integration across your entire data stack, real-time impact analysis, custom governance rule propagation, intuitive interfaces, natural language querying, and robust AI-powered capabilities. - How does data lineage help with AI-driven analytics?
Lineage provides essential context for AI, ensuring accurate data relationships and dependencies. It helps AI systems avoid “hallucinating” or generating incorrect relationships, making them reliable and effective for analytics tasks. - What are common pitfalls to avoid when selecting a lineage tool?
Avoid tools with limited integration flexibility, static or manual lineage updates, unclear scalability, high hidden costs (such as unexpected licensing fees), and those lacking intuitive user experiences or robust AI capabilities.


.png)