“It depends.”
“I’ll look into that.”
“Interesting question. I’ll get back to you.”
Data leaders want to give good, useful answers to their stakeholders, but they’re all too frequently busy giving answers like the above.
Over the past decade, data teams have transformed their tooling and infrastructure, resulting in the “modern data stack.” However, the modern data stack is a complex beast, and the solutions provided by this web of new and nuanced tools can also create new problems.
The trouble here is that closing the gap between a question asked and an answer provided can make all the difference in keeping stakeholders engaged and business leaders impressed. If data leaders can’t close the gap, the goldmine of data they’ve captured will lose its luster.
Enter the semantic layer. With a semantic layer built into the right part of their systems, data teams can build and maintain a central source of truth for the metrics stakeholders ask them about. By fully adopting dbt and building a semantic layer in the data layer, the various data teams can all share an aligned truth and turn chaos into meaning and questions into answers.
Semantic layers: The basics
What is a semantic definition?
SQL has been an essential part of the data stack for decades and is likely here to stay. It’s the most practical and useful way to query data – and every technical data analyst knows it. But SQL has one fundamental flaw: there’s no way to save calculations and logic (i.e., metrics) in SQL. SQL has to live somewhere.
In other words, SQL is not very composable. You can’t build up and reuse logic efficiently in SQL. For example, if you’re an e-commerce business and you figure out a SQL query that calculates new purchases in a given month, there isn’t a natural place to store that calculation using SQL alone.
What made dbt so popular is the ability it offered data teams to centrally manage the process of SQL transformations. With it, they can process raw data (clean, join, aggregate, and implement business logic) to create important data sets. Data transformations are an essential component of the central data model.
Even still, this process doesn’t address the need for data teams to save their calculations. They need to use a different language to define and save these semantic definitions, and this has been the classic role of BI tools for many years. BI tools were the de facto place where metrics capturing operational and business calculations were stored.
The problem is that every BI tool has its own standard for defining semantics. The proliferation of BI tools and data apps makes alignment and centralization difficult. So, at its core, the job of a semantic layer is to serve as the source of truth for all an organization’s metrics.
Why is it important to centralize metrics?
We have two opposing forces: governance, which includes the high-level need to centrally control and define metrics for the sake of consistency, and business analyst flexibility, which includes the practical need to craft logic on the fly and rapidly test new ideas.
Analyst flexibility is a critical business need, but over time, unconstrained freedom results in an overwhelming number of definitions trapped within various BI tools and data apps—often written in their own specific semantic language. Much of this might frustrate data leaders, but the need for data analysts to work with flexibility is an important one.
As we’ve written before, “Business logic doesn’t bloom behind the scenes by data engineers; it’s developed by business analysts on the front lines, as part of their everyday tasks within their native BI environments.”
And this is a problem: Over time, metrics become more useful and trustworthy the more consistent and shareable they are, but in short periods of task-specific work, flexibility rules. An effective solution requires prioritizing both needs and refusing to disregard either.
Teams need a central place to store metrics and a standard language with which every tool can use and integrate. Only then can data analysts retain flexibility while still supporting consistency. Enter the semantic store.
How do you integrate and embed the semantic store?
A semantic store is a single location a data team uses to define business concepts and calculations in data terms. It allows stakeholders to ask business questions (e.g., “Why was conversion up last week?”) that correspond to agreed-upon data results (e.g., “conversion,” as signing up for a demo instead of clicking a CTA button or making a full purchase).
A central semantic store helps ensure data results are reliable, so your team knows a conversion yesterday will still be accounted for as a conversion tomorrow; it ensures data is consistent, so anyone on your team and beyond it knows what someone else means when they say “conversion”; and it keeps data flexible so that you can apply the same definition for different applications.
In fact, a central metrics store accelerates the pace of data product creation. Analysts don’t need to spend time figuring out a definition’s meaning or choosing which calculation to use.
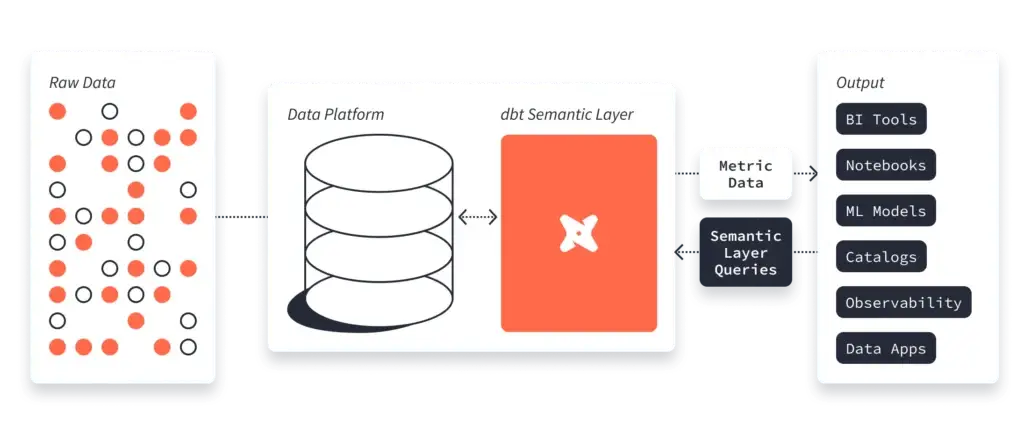
(Source)
With a metrics store, you can provide centralization and standardization, making implementation simple while retaining flexibility. There are different approaches to implementing a semantic store for data analytics. One of them is the “universal semantic layer.”
A universal semantic “layer,” as you can see in the diagram above, is an independent layer that lies between raw data assets (e.g., a data warehouse or lakehouse) and data consumers (e.g., BI tools or AI/ML platforms). It functions both as a source of truth and as a means of translation between sources of data and users that consume the data. Once implemented, data teams can use a universal semantic layer and a standard semantic language to code metrics, and analysts can use these definitions as objects to create queries they consistently need.
With a universal semantic layer, consensus is pre-established, and a foundation for making meaning is already laid. Even more importantly, different types of users using different tools, interfaces, and applications can work knowing they’re all aligned and using consistent definitions. Generative AI tools, for example, rely on this kind of pre-established consensus, making central semantic stores an even more important part of the data stack.
Why do you need to build a central source of truth for business logic?
At first glance, keeping track of the truth should be easy. Data teams might start small, but once you build a stack, it should be as simple as keeping up with business growth.
Data, of course, is anything but simple. Complexity doesn’t grow linearly; as businesses grow, they add new teams, tools, functions, and lines of business. Some will eventually be retired, some will grow wildly in usage, and others will be retained despite being little more than tech debt. Like cells undergoing mitosis, data sources grow, strain against their limits, become too complex, subdivide, and start growing again.
When the company was young and the data team small (maybe even just one person), it might have seemed like you could keep up on a relatively casual basis. The knowledge contained in a small team’s heads was good enough.
As companies evolve and add more people to the data team, they add data warehousing solutions like Snowflake, Bigquery, DataBricks, and Redshift to capture and better centralize more data. Each business domain operates independently and often uses its own tools. As a result, various data users—including data scientists and analysts—and systems like BI tools, ML notebooks, and reverse ETLs often rely on definitions that are rarely aligned and consistent.
Here, the modern data stack you’ve worked so hard on can start to work against you. As Tristan Handy, CEO at dbt labs, writes, modern data stacks now tend to comprise many different tools, and “the modular architecture can be a bit overwhelming due to the number of different tools working in consort. It can be unclear where the boundaries for one tool stop and the next one start.”
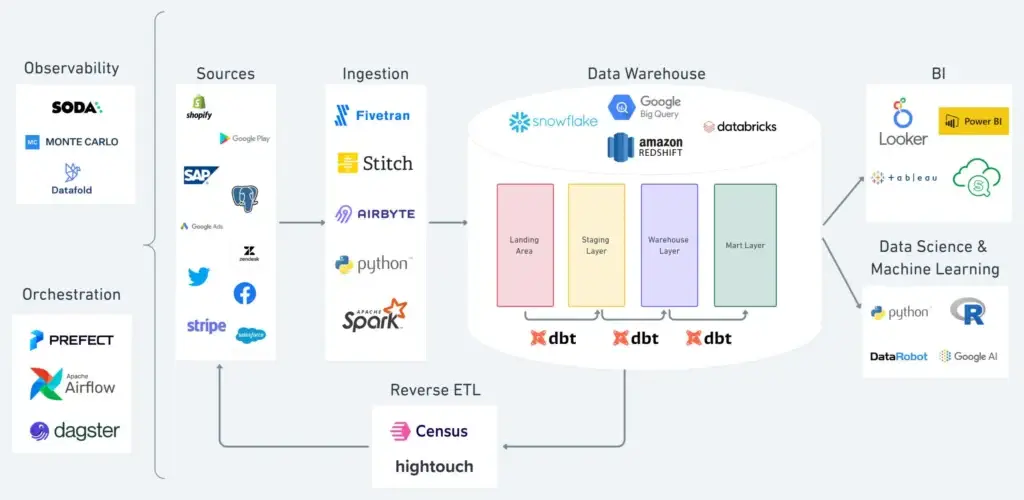
(Source)
Of course, modularity has its benefits, including enhanced flexibility and the ability to integrate various data apps across different business domains. However, as the number of data apps and types of data users grow, so do the risks of inconsistencies, duplicates, conflicts, and siloed definitions. Eventually, serious inconsistencies can lead to chaos, which eventually leads to a loss of trust in data-driven decision-making.
Before too long, the need for a data model that provides a central and aligned source of truth for metrics arises. With a shared data model, different users can look to centrally managed business logic and allow all data apps and users to use consistent and aligned definitions. They can then share new metrics and calculations with other domains by introducing them to the central data model.
Even great data and great data teams can struggle to make meaning if consensus isn’t built-in. Ultimately, a central data model is the only scalable way to build and maintain a modern data stack that enables self-serve data exploration and analytics.
Semantic layers and Semantic stores: An overview of the options today and the emergence of dbt as the new standard
The case for semantic layers is compelling, but figuring out which approach is best for your particular use case – and how best to integrate it – is a nuanced decision.
The primary thing to keep in mind is that almost every BI tool has its own semantic language for defining metrics. Looker, for example, has LookML. But there are other options to examine, too, which work as universal semantic layers.
LookML, short for Looker Modeling Language, is the language Looker offers for creating semantic data models. With LookML, data teams can describe and define a wide range of dimensions, metrics, and calculations within their central repository. Similar concepts are found across similar tools, such as Apache Superset, an open-source tool, and Tableau Pulse, built on the Tableau platform.
Cube and Atscale, in contrast, are examples of universal semantic layers that integrate with all BI tools and centralize a company’s data so that data users can share definitions across Google Sheets, notebooks, BI tools, reverse ETLs, and more.
dbt is an open-source package that allows data teams to model data via templated SQL. In 2023, dbt Labs acquired Transform, which provided a sophisticated metric framework based on MetricFlow. In October of that same year, dbt announced the general availability of the dbt Semantic Layer. dbt was already a core part of many data stacks, having long become an industry standard for transformations, but after this acquisition and the introduction of open-source packages for semantics, the dbt semantic layer is poised to become the new standard by which data teams determine semantic consensus and centrally define their metrics right alongside their dbt models.
As Tristan Handy, founder & CEO of dbt Labs, writes, “The modern data stack was built around SQL. Circa 2020, SQL was probably the only standard that mattered very much.” Now, however, a range of standardization opportunities has arisen, including file format (with Delta, Iceberg, and Hudi), data interchange (with Apache Arrow), and, of course, semantic layers – with dbt leading the way.
If a standard for semantic information emerges, Handry writes, “Users will finally be able to decouple their business logic from their reporting, freeing them to adopt a wider array of purpose-built analytical tools.” With the introduction of dbt’s semantic layer, data teams now have the power to manage their entire data model (SQL transformations and semantics) within the dbt standard, enjoying all of dbt’s advantages such as version control, testing, documentation, CI/CD, etc.
Three reasons why you should build a semantic layer in the data layer
Especially as dbt standardizes, a semantic layer – functioning as a central source of truth for metrics – is most effective when it’s implemented in the data layer and not the consumption / BI layer.
Ultimately, there are too many users of too many different tools to rely on definitions housed only within BI platforms. Like a dictionary that sets up basic definitions before writers start writing, truth has to lie within the data layer itself before it’s consumed and used.
To see why, we can map the advantages of building a semantic layer in the data layer back to the values we identified earlier: reliability, consistency, and flexibility.
Reliability
A semantic layer needs to offer reliability, meaning a business concept defined yesterday will mean the same thing tomorrow. Reliability allows people inside and outside to depend on metrics for business decisions. Even a little instability can make people trust their metrics less.
A semantic layer built into the data layer allows you to define metrics once and reuse them. An “active user” or “session,” for example, has to mean the same thing from day to day and from team to team. This is especially practical with dbt, which makes metric reusability a core feature.
Consistency
A semantic layer needs to provide consistency, meaning the avoidance of conflicting and contradictory terms. Consistency ensures data teams don’t mistakenly use terms with similar names that have different calculations or definitions. Similarly, it ensures teams don’t accidentally use duplicates – terms with similar definitions but different names.
With a semantic layer built into the data layer, data teams and analysts can pre-define a foundational consensus that exists prior to any form of data consumption. With each metric defined and agreed upon, data teams can collaborate more effectively with each other and across the company.
Flexibility
A semantic layer needs to offer flexibility, meaning it allows people to use these predefined metrics in a range of different contexts. If definitions are housed within different BI platforms, what appears to become consensus can become chaotic as different teams collaborate.
When metrics are centralized in the semantic layer, and the semantic layer is built into the data layer, those metrics become accessible from any analytics tool. dbt, in particular, due to its many different integrations, also becomes compelling for this reason.
Going all-in on dbt with Euno
Once you adopt dbt for data transformations, it makes the most sense to use it to manage your semantic definitions, too. Sometimes, data teams hesitate to put too much pressure on one tool – remember the emphasis on modularity we mentioned earlier – but some tools only offer their greatest benefits when you push them.
By going all in on dbt, you can extend many of the same benefits you likely already relish for data transformation to semantic definitions. You can then decouple your business logic, including transformations and semantics, from the BI layer – allowing you to build a whole that’s greater than the sum of its parts.
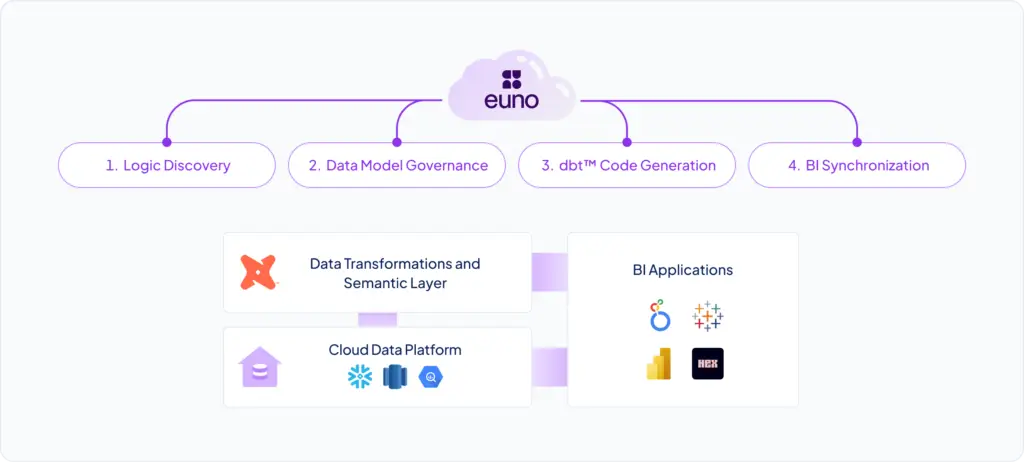
Of course, diving into dbt doesn’t solve everything. The main challenge that follows is teaching a new semantic language, curating and building the metrics in dbt, and making sure the data model and semantics in dbt remain in complete sync with all your BI tools. This is where Euno comes in. With Euno, you can build a centralized metrics repository in dbt and offer uniform logic sharing to your data users within their chosen BI tools.
Euno enables data users to dynamically query dbt-metrics within their chosen BI tools, automatically translating semantic definitions into SQL for consistent calculations. On top of that, data teams can use Euno to promote measures and metrics defined in BI tools by automatically codifying them in dbt™/MetricFlow, adding them to the centrally governed semantic layer.
Request a demo to watch Euno in action.