Top 5 must-have features for a modern Metadata Catalog in 2025


What is a metadata catalog?
If you had a magic crystal ball, what question would you ask it about your data assets?
- How is a specific metric calculated?
- Which tables weren’t created from a dbt model but are still highly used?
- Which model contains JOINs with fan-out?
These aren’t trivial questions. They’re the kind of questions data teams ask every day. The answers exist in your metadata, but they’re scattered across tools, hidden in pipelines, or buried in SQL queries. This is where a metadata catalog comes in. It centralizes metadata, making it easy to search. It tracks and connects the dots across your data ecosystem and provides context to help teams get reliable answers easily and consistently.
Metadata catalog vs. data catalog: What’s the difference?
A data catalog and a metadata catalog may sound similar, but they serve different users and goals.
A data catalog is designed for analysts and business users. It focuses on searchability and collaboration, helping users find and understand datasets that they need for reporting and analysis.
A metadata catalog is built for data teams. Its primary goal is enforcing standards, ensuring data governance, and providing visibility into data lineage, transformations, and usage.
A data catalog helps analysts find the data, while a metadata catalog helps data teams manage and trust it. Both are important, but if you care about governance, standardization, and how data flows across your stack, a metadata catalog is essential.
However, not all metadata catalogs are created equal. A modern metadata catalog must do more than store information, it needs to provide intelligence and actionability. If you’re evaluating metadata catalogs, here are the five essential features to consider.
Key features of a metadata catalog
1. Breadth: Covering your data ecosystem
Modern data ecosystems are vast. They include data warehouses, lakehouses, ingestion tools, transformation tools, notebooks, BI tools and AI agents. A metadata catalog is only useful if it connects to your main data stack.
It’s not about having the longest list of integrations. It’s about having the right integrations and the ability to customize them according to your needs.
2. Depth: Surface metadata is not enough
Most metadata catalog tools will tell you the basics—type, owner, last update, description, and tags. That’s fine for organizing data, but it won’t help you understand what really matters.
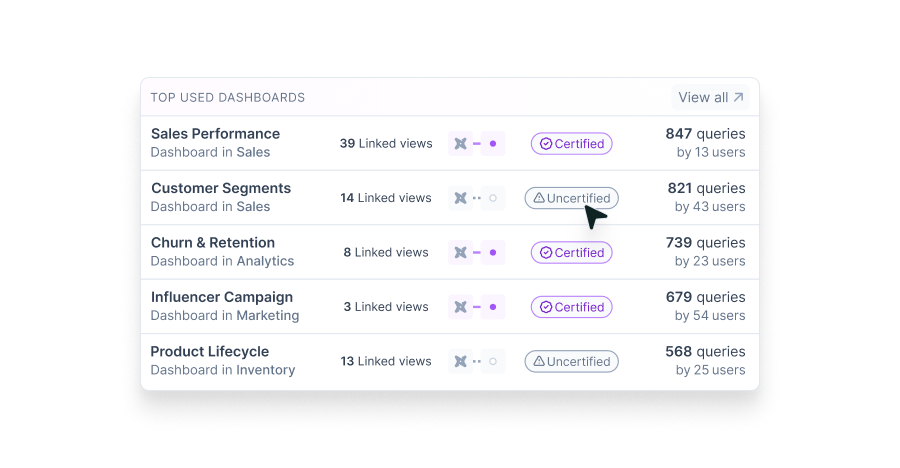
Usage data is the most important metadata for most analytics and data engineering use cases. It’s the main way to understand how business terms and metrics are actually used by the business, among countless conflicting definitions that usually exist in the data stack.
This is especially true for federated analytics environments. If you’ve got 100 analysts managing 20,000 dashboards, good luck figuring out which ones actually matter. Without usage insights, you end up with a mess: stale, duplicate, and irrelevant assets everywhere.
Usage tracking is also a governance necessity. High-usage assets need to be properly managed to prevent inconsistencies and misinformation from spreading and to empower their reuse. Conversely, unused assets need to be shut down and retired. A strong metadata catalog ensures that the most-used data is accurate, and governed, so teams can trust the insights they rely on, and maintain a high level of hygiene to support agile changes.
It’s not just about how often an asset is used. It’s also about who’s using it. A good catalog should show distinct user counts and even list them. That insight helps teams really understand what the most valuable data assets are and take action on them.
3. Connectivity: Carrying information across technologies
It’s easy to check how many views a report has in Tableau, that’s already built into the tool. But what if you need to trace usage back to the source? For example, you might want to: list all tables in Snowflake that weren’t created by dbt but are in high usage by the sales team in Tableau.
That’s where things get complicated. The information exists, but it’s scattered across different products. Snowflake logs table queries, dbt tracks transformations, and Tableau records report usage, but these tools don’t automatically connect. Without a way to carry metadata across technologies, data teams struggle to get a full picture of how data is used along the stack.
This is useful for retrieval, but it’s mandatory for governance initiatives. Data teams need to identify inconsistencies to enforce standards, and without clear visibility across systems, maintaining trust in data becomes a manual, error-prone process.
4. Customizability: Making your catalog future proof
No two data operations are the same, and even within the same organization, priorities shift, technologies change, and what matters today may not be what matters tomorrow. A good metadata catalog should give teams the flexibility to define the metadata that actually matters to them, both now and in the future.
Most metadata catalogs come with 100-300 predefined metadata attributes—but they’re built around someone else’s idea of what’s important. A great catalog doesn’t force you into rigid definitions—it lets you define your own properties so you can track what’s actually important to your data operation.
There are two types of custom properties that a great catalog should support:
1. Fixed Properties
These are manually input by users and remain unchanged regardless of upstream or downstream activity. For example, you might want to assign an SLA to a dataset. Since this classification is independent of lineage or usage changes, it stays static unless manually updated.
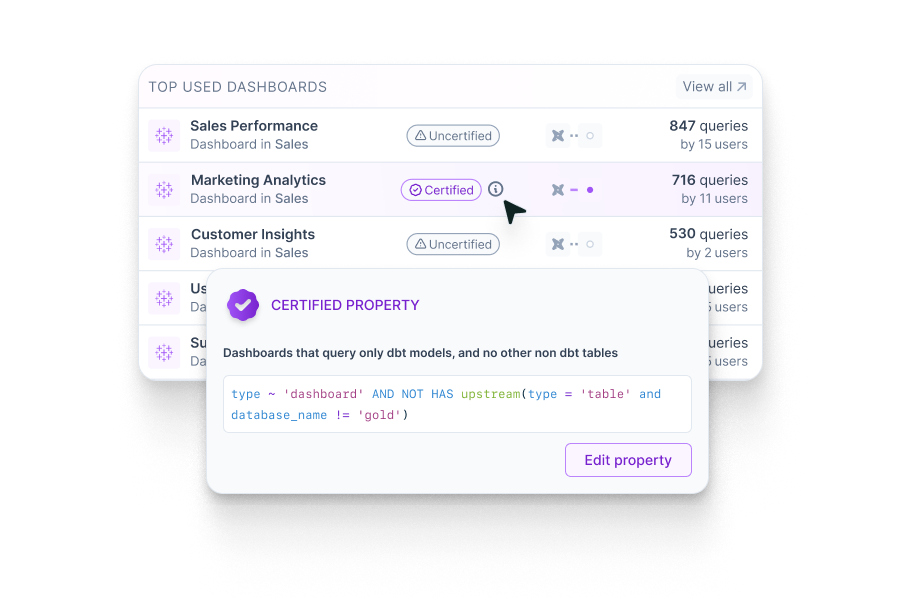
2. Live Properties
Unlike fixed properties, live properties adapt to changes across the data stack. These are dynamic attributes that update based on upstream or downstream activity.
Take “certified dashboard” as an example. Whether or not a Looker dashboard meets this condition depends on transformations built by users upstream. This means the catalog must track live metadata and reflect real-time changes.
Custom properties are very powerful when used to automate governance.
Imagine you’re democratizing dbt model contributions and want to ensure that only reliable models get promoted and get the coveted “gold_standard” tag. Instead of manually reviewing each model, you define a custom property called “Eligible for Promotion”, which requires, for example, that:
- A description exists
- It has an owner
- Tests are in place
- The model has been running successfully for 14 days
- The average runtime is under 10 seconds
- Only depends on “gold_standard” sources
Each of these conditions is already tracked in the catalog. By aggregating them into a custom property, you make governance scalable, enforceable, and easy to act on. A great metadata catalog should let you configure custom properties, ensuring teams can set rules, track compliance, and take action, without relying on manual checks.
5. Searchability: Making metadata easy to find
Metadata is only useful if you can actually find what you need, quickly. A metadata catalog should provide an interface that makes searching fast, flexible, and intuitive. At the most basic level, that means being able to filter, sort, and customize views to focus on relevant data. But a modern catalog should go much further.
Since the end users of a metadata catalog are data people, they should be able to search in a way that feels natural to them. A great catalog should provide a query language that allows teams to retrieve exactly what they need. For example, you should be able to run queries like:
Find all dbt models that depend on dbt sources in the Salesforce database schema.
Or…
Find Looker dashboards in the Sales folder that depend on a specific Snowflake table.
And in the AI era, there’s no reason users should have to write complex queries themselves. AI can generate the query for you, translating a natural language question into a structured query.
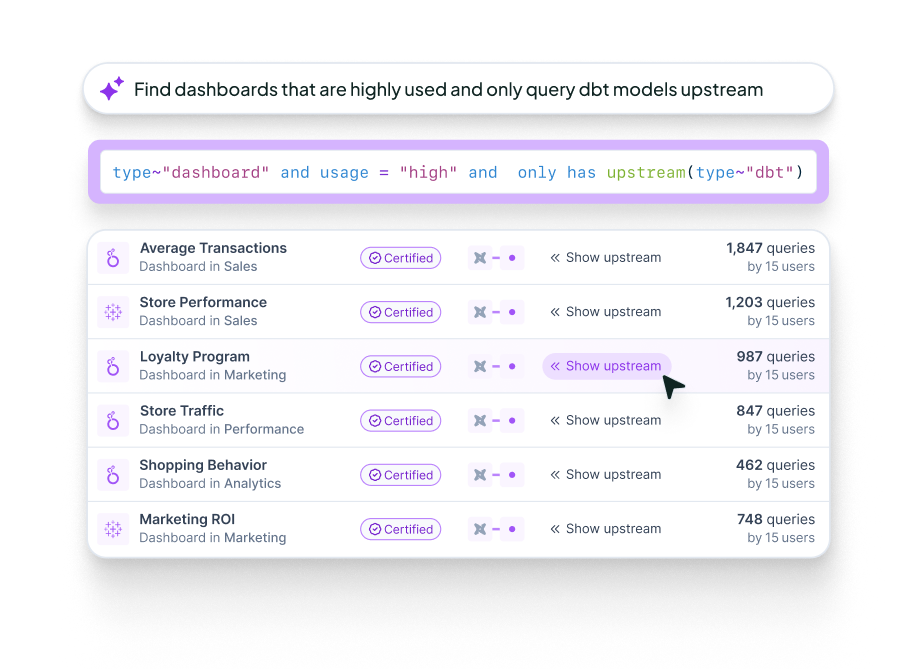
Even more powerful is the ability to combine search with custom properties. Imagine you’ve defined a property called Eligible for Promotion for dbt models. You should be able to ask:
Which dbt models are not eligible for promotion, and who owns them?
With a single query, you surface models that don’t meet governance standards and the responsible owners, without manually piecing information together. A modern metadata catalog should meet data teams where they are, whether through a familiar query language or AI-powered search. It will ensure metadata is not just stored but easily accessible and actionable.
The growing importance of metadata catalogs in the AI era
AI and metadata have a two-way relationship. AI needs metadata to function properly, and metadata management needs AI to be effective.
AI needs metadata
AI-powered analytics is only as good as the data it relies on. Without metadata, AI doesn’t know which datasets are reliable, certified, or even actively used. That’s how bad insights happen. A metadata catalog provides the trust layer AI needs, answering key questions like: Is this data asset certified? Where does the data come from? How is a metric calculated? Who uses it? Without these signals, AI isn’t making smart decisions, it’s just guessing.
Metadata needs AI
AI isn’t just a consumer of metadata, it should also improve how metadata is managed. We’ve already talked about querying metadata in natural language, but AI can go much further. Let’s say you want to govern fact tables and ensure they don’t contain cross joins. Instead of manually checking SQL, you can create a custom property called Cross Join Compliance that tracks whether a fact table follows best practices. Plus, use AI to scan SQL code, detect cross joins, and automatically update the property’s status.
Instead of writing policies that no one follows, AI enforces them automatically and keeps governance proactive.
The benefits of implementing a metadata catalog
A metadata catalog isn’t just a repository, it’s the foundation for governance, automation, and AI-powered analytics. When evaluating a metadata catalog, consider these key benefits:
Covers your data stack: Connects seamlessly to your tools, from ingestion and transformation to BI and AI platforms.
Gives you the full picture: Tracks not just basic metadata but also usage and dependencies to help teams focus on what matters.
Bridges the gaps between technologies: Ensures metadata flows across tools, making it easier to understand how data moves through your ecosystem.
Adapts to your needs: Supports custom properties, so you can automate governance and enforce best practices.
Makes metadata instantly searchable: Enables powerful search, whether through structured queries, AI-powered natural language search, or custom metadata properties.
Automates governance with AI: Uses AI to enforce standards, scan SQL for compliance, and keep your metadata clean and reliable.
See it in action with Euno
Euno brings all of these capabilities into a single platform, making metadata actionable, trustworthy, and easy to manage. Book a demo today and see how Euno can transform the way you manage metadata.