The road to AI begins with trusted data products

99% of data leaders say data is critical to their organization, yet 97% face challenges using it effectively. The reason? A lack of trust in their data. And now, generative AI is making this problem worse.
Over the last decade, data stack technology advancements have revolutionized how businesses handle data, enabling data-informed decision-making, real-time personalization, predictive analytics, and more.
With the arrival of GenAI, CDAOs and executives across the globe are looking for ways to quickly realize the potential economic value of AI for their businesses.
For years, self-serve analytics has been a goal for data teams, empowering business users to access and explore data without relying on intermediaries. But the arrival of Generative AI is transforming that aspiration into a tangible possibility, making data insights available more quickly and easily.
Imagine a world where business users can simply ask, in natural language, for the specific data they need and instantly receive accurate, actionable insights. GenAI offers the potential to break down barriers between business teams and data.
But there’s a catch: the foundation for such capabilities lies in data trust and governance. Without trusted, high-quality data assets, even the most advanced AI models will produce unreliable or misleading results.
According to Talend’s Data Health Barometer Report from 2022, 99% of data experts and leaders believe that data is important to their organization. Yet, despite believing this, 97% of data leaders say they face challenges in using their data–with data quality being the top reason for these challenges. Additionally, 36% of respondents pointed to trusting data to make business decisions as a key hurdle. When decision-makers cannot trust the accuracy, consistency, and governance of their data, it undermines their ability to drive impactful outcomes.

A persistent challenge: “We can’t trust these numbers”
The speed and flexibility of modern data tools have come at the cost of accuracy and alignment. While the modern data stack has had a revolutionary impact, it has also exacerbated fundamental issues with data trust and consistency.
If you’ve worked on a data team for any amount of time in the last 10 years, let Lauri Hänninen paint a familiar picture for you:

You’ve probably lived through a similar scenario. The cycle goes something like this–the business wants to move quickly to generate new information from data. With the modern data stack increasing access to data across the business, data teams have moved towards “self-serve” analytics models. Data teams create the pipelines and provide access to data through easy to use BI tools, and business users create their own reports and dashboards.
An unfortunate side effect of the self-service model is that different teams end up creating conflicting information due to varying methodologies of calculating business logic. Limited upfront planning leads to significant inconsistencies downstream, and the business has trouble making sense of any of the information they have.
More often than not, the problem of data quality is not a tooling issue–it’s a human process issue. People are misaligned on the meaning of different business concepts, and this results in incorrect or inconsistent data.
The promise and pitfalls of AI
Organizations are well along the hype cycle of AI–and eager to reap the promised economic benefits. McKinsey has estimated that generative AI could unlock $2.6 trillion to $4.4 trillion annually across industries, and Bill Gates has called AI “the most significant tech advancement of our time”.
Many companies even look towards AI to replace large portions of their workforce. However, not many are ready to discuss the elephant in the room–AI is only as powerful as the data that feeds it—without clean, governed, and well-aligned data, it may become more of a liability than a business advantage.
“As a leader, it’s critical to recognize that data – its quality, diversity, governance, and operational pipelines – will make or break your generative AI initiatives. World-class generative AI is simply not possible without world-class data.” (Source: AWS Cloud Enterprise Strategy Blog, May 2024).
The challenge lies in ensuring the data AI runs on is both consistent and trustworthy. Without clear governance, AI agents can’t differentiate between official definitions and exploratory work. This lack of understanding leads to conflicting outputs and erodes trust in the results.
This is where a governed semantic layer comes in–a potential solution to the challenge of inconsistent data and unreliable AI outputs.
Governed semantic layers to the rescue
A semantic layer is like a universal translator for your data–it standardizes business logic, ensuring everyone speaks the same language when analyzing data. For AI, it’s even more crucial: it provides consistent data interpretation and enables LLM-based tools to accurately map business intent to data.
If you haven’t heard of semantic layers or semantic models before, you have probably already used one. They have been around for years, buried deep inside of business intelligence tools, but the term “semantic layer” has gained traction in recent years.
Semantic layers help solve a large portion of data quality issues, by providing alignment and standardization of business logic.
Looker pioneered the first ‘codified’ semantic layer with LookML. It became a popular tool among data teams, enabling BI developers to govern key business logic like joins, measures, and dimensions.
Since then, many semantic layers have followed. Some of the well-known players in the market today include Looker (still going strong), Cube, and dbt Cloud, which are now working on decoupling the semantic layer from the BI layer so that additional data applications –including AI can also leverage these business definitions.
However, the human problem still remains–if the semantic layer does not stay aligned with the speed of changes and business logic developments across the business, it gets stale, and business users will continue to do what they have always done–figure sh*t out and do it themselves.
Keeping a semantic layer fresh and relevant becomes a full-time job for data teams–something impossible to keep pace with. The data team is often unaware or cannot move fast enough to keep pace with changing business logic. As a result, the semantic layer also fails to solve the problems of data quality.
Solving data quality with governance and certification
So, first things first—you need to create a system that makes it easy for data teams to govern the semantic layer. A governed semantic layer is essential for unlocking text-to-SQL, allowing business users to ask questions in natural language and instantly get accurate, reliable answers.
But this is only the first step. Business users need more than ad-hoc answers—they need context. This is where text-to-reports/dashboards comes into play, enabling users to access, on-demand, relevant data products, providing them with the broader view required for informed decision-making.
To achieve this, you need to certify your data products—your reports and dashboards. This must build on the semantic layer while incorporating additional criteria to ensure that all data products meet the highest standards of trust and reliability.
Let’s dive in.
Make your data product AI ready
Ensuring data quality and reliability doesn’t happen overnight. It requires a structured approach. By focusing on three key steps, organizations can establish a strong foundation for trustworthy AI for data analytics. The process begins with building a governed semantic layer, moves to certifying data products like reports and dashboards, and finishes with connecting AI agents to these trusted assets. Each step reinforces the next, creating a scalable framework for consistent, reliable insights.
Step 1: Establish a governed semantic layer
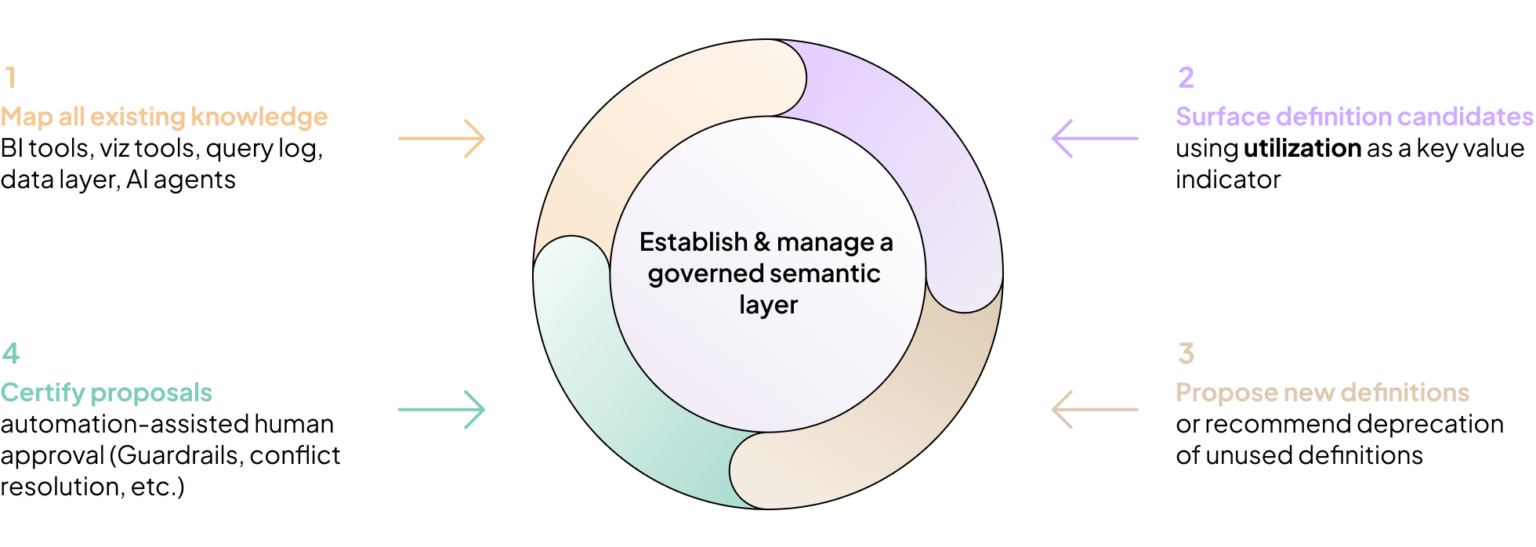
As we’ve discussed, ensuring that the semantic layer is constantly aligned with evolving business needs is a difficult endeavor. Business logic changes constantly (that’s what data analysts do), and a stale semantic layer can’t deliver reliable results. That’s why we recommend using utilization insights to understand where the effort needs to go and to guide the process.
Start by mapping all existing knowledge—BI tools, visualization tools, query logs, the data layer, and even AI agents. Next, determine which definitions are the most valuable and commonly utilized, meaning that they should be the first to be added to your semantic layer. Definitions that show high usage, especially across different teams and users, are strong indicators of value. Once identified, resolve any conflicts between overlapping definitions and codify the agreed-upon versions into the semantic layer to ensure consistency and accessibility.
This is not a one-time process. New business definitions are created all the time, so you need to continuously monitor usage to understand what really matters. When a new definition starts gaining traction, you should be notified to evaluate whether it’s worth adding to the semantic layer or replacing an existing definition. This ensures the semantic model stays dynamic, relevant, and aligned with evolving business needs.
This approach lays a solid foundation for text-to-SQL. AI agents can now accurately answer questions like “What was our MAU (Monthly Active Users) last month?” with confidence. But while this is a big step forward, it’s not enough. Business users often need more than accurate numbers, they need context. To go beyond text-to-SQL and deliver true value, you also need to address how data products themselves are organized and governed. This brings us to the next step.
Step 2: Certify your data products
Once your semantic layer is in place, it’s time to certify your data products. Start by defining what “certified” means for your organization. This might include criteria such as:
- Does it query dbt models deployed by the data team?
- Does it rely on governed metrics from the semantic layer?
- Does it have a clear owner?
- Do the underlying tables have a production tag?
Only data products that meet these requirements should be certified. For those that don’t, it’s important to provide clear steps to help business users certify their data products. This approach encourages alignment with governance standards and promotes the use of trusted resources defined in the semantic layer.
Data products should be continuously monitored to ensure compliance with certification rules. If a change violates a rule, the product will lose its certification. Users should receive guidance on how to remediate the issue and bring the product back into compliance, ensuring governance remains relevant over time.
Knowing which data products are certified—and being able to trust them—is key to enabling text-to-dashboards and text-to-report and unlocking real business value.
Step 3: Connect AI agents to certified data assets
The final step is to connect your AI agents to your certified data assets: tables, metrics, and products. This ensures AI agents rely on trusted, governed assets only, enabling them to deliver accurate and reliable insights.
Additionally, query and utilization insights from both AI agents and business users should feed back into your semantic layer. This continuous feedback loop helps refine the semantic layer, prioritize high-value assets, and further optimize AI integration.
By aligning your AI agents with your most reliable data products and iteratively improving your semantic layer, you create a system that evolves with your organization’s needs and ensures value over time.

Certified Data Products–a whole new world of possibilities
By following these three steps, data teams can manage and govern their data products. This is the ultimate goal of all data teams: metrics standardization, real-time consistency, and avoiding business misalignment and data quality issues.
The modern data stack has brought incredible advancements, but governance and alignment remain critical gaps that cannot be ignored. Without them, even the most advanced tools and AI integrations risk falling short of their potential, leaving organizations struggling with trust, accuracy, and agility in their data-driven decision-making.
By proactively managing their certified data products your business can turn data challenges into opportunities.


.png)